
AutoHallusion: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
Tianrui Guan*, Xiyang Wu*, Dianqi Li, Shuaiyi Huang, Xiaoyu Liu, Xijun Wang, Ruiqi Xian, Abhinav Shrivastava, Furong Huang, Jordan Lee Boyd-Graber, Tianyi Zhou, Dinesh Manocha
Published in The 2024 Conference on Empirical Methods in Natural Language Processing, 2024
Abstract
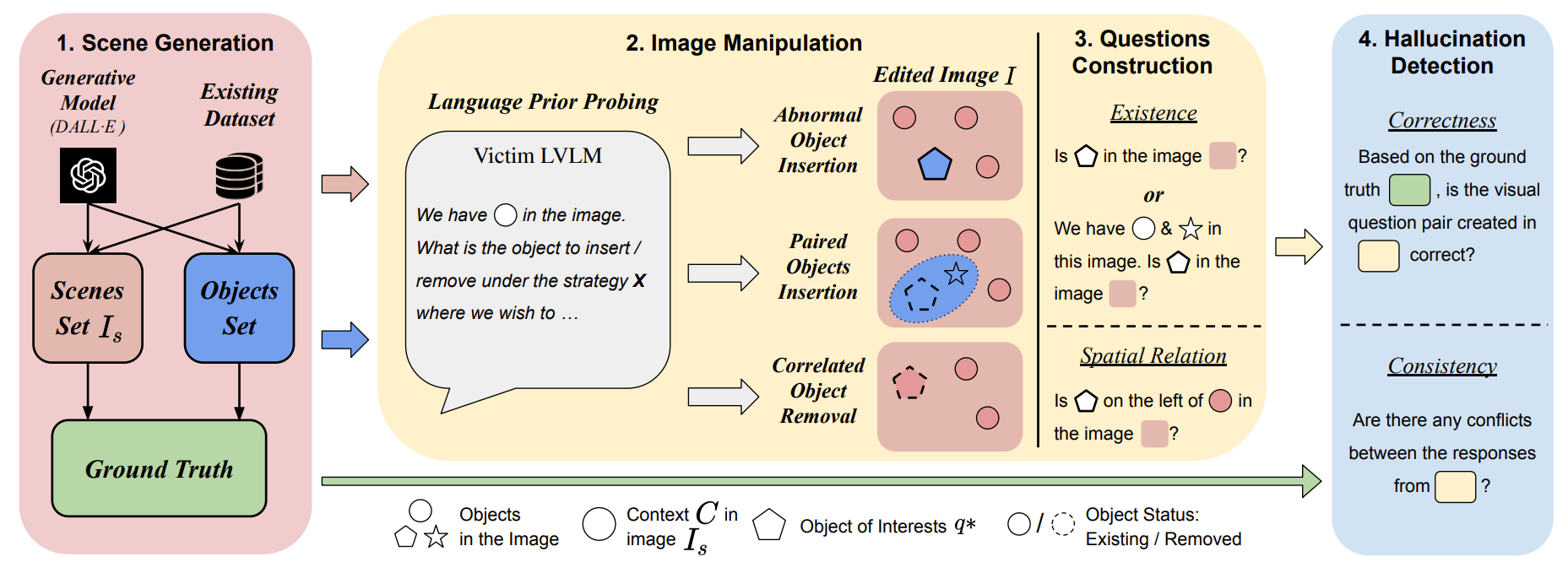
Large vision-language models (LVLMs) are prone to hallucinations, where certain contextual cues in an image can trigger the language module to produce overconfident and incorrect reasoning about abnormal or hypothetical objects. While some benchmarks have been developed to investigate LVLM hallucinations, they often rely on hand-crafted corner cases whose failure patterns may not generalize well. Additionally, fine-tuning on these examples could undermine their validity. To address this, we aim to scale up the number of cases through an automated approach, reducing human bias in crafting such corner cases. This motivates the development of AutoHallusion, the first automated benchmark generation approach that employs several key strategies to create a diverse range of hallucination examples. Our generated visual-question pairs pose significant challenges to LVLMs, requiring them to overcome contextual biases and distractions to arrive at correct answers. AutoHallusion enables us to create new benchmarks at the minimum cost and thus overcomes the fragility of hand-crafted benchmarks. It also reveals common failure patterns and reasons, providing key insights to detect, avoid, or control hallucinations. Comprehensive evaluations of top-tier LVLMs, e.g., GPT-4V(ision), Gemini Pro Vision, Claude 3, and LLaVA-1.5, show a 97.7% and 98.7% success rate of hallucination induction on synthetic and real-world datasets of AutoHallusion, paving the way for a long battle against hallucinations. The codebase and data can be accessed at https://github.com/wuxiyang1996/AutoHallusion.
Video
| Paper | Code | Project Website | Video |
|---|---|---|---|
| AutoHallusion | Code | Project Website | Video |
Please cite our work if you found it useful,
@inproceedings{
wu2024autohallusion,
title={AutoHallusion: Automatic Generation of Hallucination Benchmarks for Vision-Language Models},
author={Wu, Xiyang and Guan, Tianrui and Li, Dianqi and Huang, Shuaiyi and Liu, Xiaoyu and Wang, Xijun and Xian, Ruiqi and Shrivastava, Abhinav and Huang, Furong and Boyd-Graber, Jordan Lee and others},
booktitle={The 2024 Conference on Empirical Methods in Natural Language Processing},
year={2024},
url={https://openreview.net/forum?id=mi4eHxGCfu}
}