
AutoHallusion: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
Tianrui Guan*, Xiyang Wu*, Dianqi Li, Shuaiyi Huang, Xiaoyu Liu, Xijun Wang, Ruiqi Xian, Abhinav Shrivastava, Furong Huang, Jordan Lee Boyd-Graber, Tianyi Zhou, Dinesh Manocha
Published in The 2024 Conference on Empirical Methods in Natural Language Processing, 2024
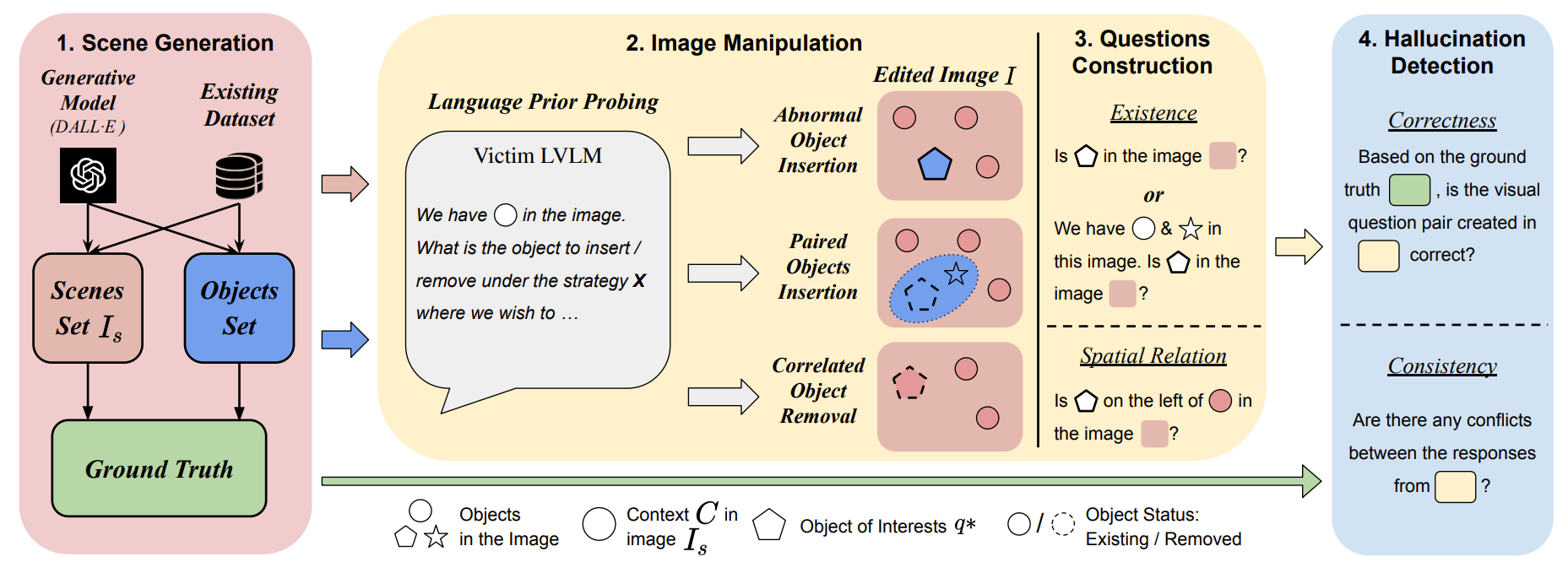
Large vision-language models (LVLMs) are prone to hallucinations, where certain contextual cues in an image can trigger the language module to produce overconfident and incorrect reasoning about abnormal or hypothetical objects. While some benchmarks have been developed to investigate LVLM hallucinations, they often rely on hand-crafted corner cases whose failure patterns may not generalize well. Additionally, fine-tuning on these examples could undermine their validity. To address this, we aim to scale up the number of cases through an automated approach, reducing human bias in crafting such corner cases. This motivates the development of AutoHallusion, the first automated benchmark generation approach that employs several key strategies to create a diverse range of hallucination examples. Our generated visual-question pairs pose significant challenges to LVLMs, requiring them to overcome contextual biases and distractions to arrive at correct answers. AutoHallusion enables us to create new benchmarks at the minimum cost and thus overcomes the fragility of hand-crafted benchmarks. It also reveals common failure patterns and reasons, providing key insights to detect, avoid, or control hallucinations. Comprehensive evaluations of top-tier LVLMs, e.g., GPT-4V(ision), Gemini Pro Vision, Claude 3, and LLaVA-1.5, show a 97.7% and 98.7% success rate of hallucination induction on synthetic and real-world datasets of AutoHallusion, paving the way for a long battle against hallucinations. The codebase and data can be accessed at https://github.com/wuxiyang1996/AutoHallusion.
AGL-NET: Aerial-Ground Cross-Modal Global Localization with Varying Scales
Tianrui Guan*, Ruiqi Xian*, Xijun Wang, Xiyang Wu, Mohamed Elnoor, Daeun Song, Dinesh Manocha
Published in The 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024
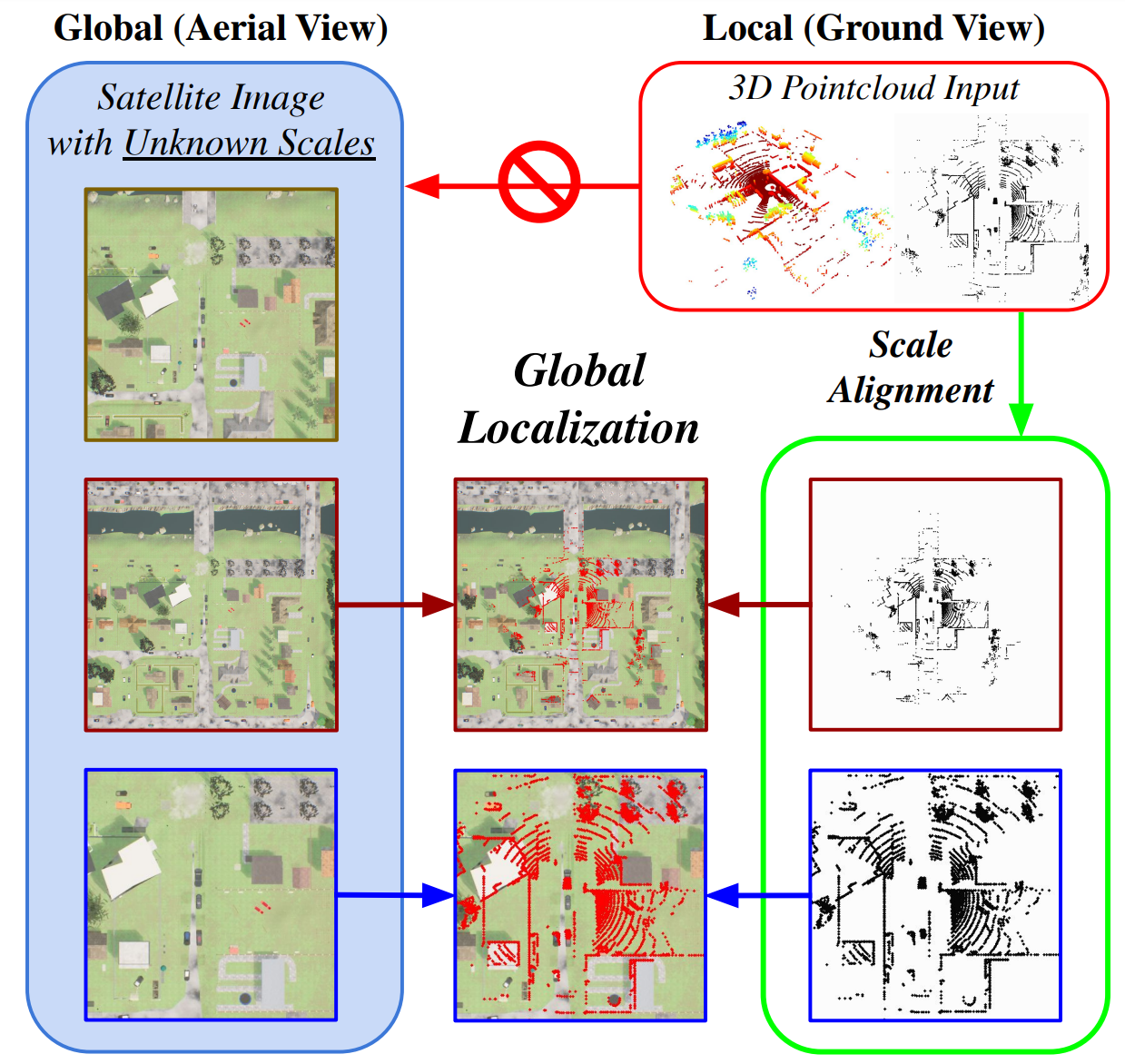
We present AGL-NET, a novel learning-based method for global localization using LiDAR point clouds and satellite maps. AGL-NET tackles two critical challenges: bridging the representation gap between image and points modalities for robust feature matching, and handling inherent scale discrepancies between global view and local view. To address these challenges, AGL-NET leverages a unified network architecture with a novel two-stage matching design. The first stage extracts informative neural features directly from raw sensor data and performs initial feature matching. The second stage refines this matching process by extracting informative skeleton features and incorporating a novel scale alignment step to rectify scale variations between LiDAR and map data. Furthermore, a novel scale and skeleton loss function guides the network toward learning scale-invariant feature representations, eliminating the need for pre-processing satellite maps. This significantly improves real-world applicability in scenarios with unknown map scales. To facilitate rigorous performance evaluation, we introduce a meticulously designed dataset within the CARLA simulator specifically tailored for metric localization training and assessment. The code and data can be accessed at https://github.com/rayguan97/AGL-Net.
Highlighting the Safety Concerns of Deploying LLMs/VLMs in Robotics
Xiyang Wu, Souradip Chakraborty, Ruiqi Xian, Jing Liang, Tianrui Guan, Fuxiao Liu, Brian Sadler, Dinesh Manocha, Amrit Singh Bedi
Published in arXiv:2402.10340, 2024
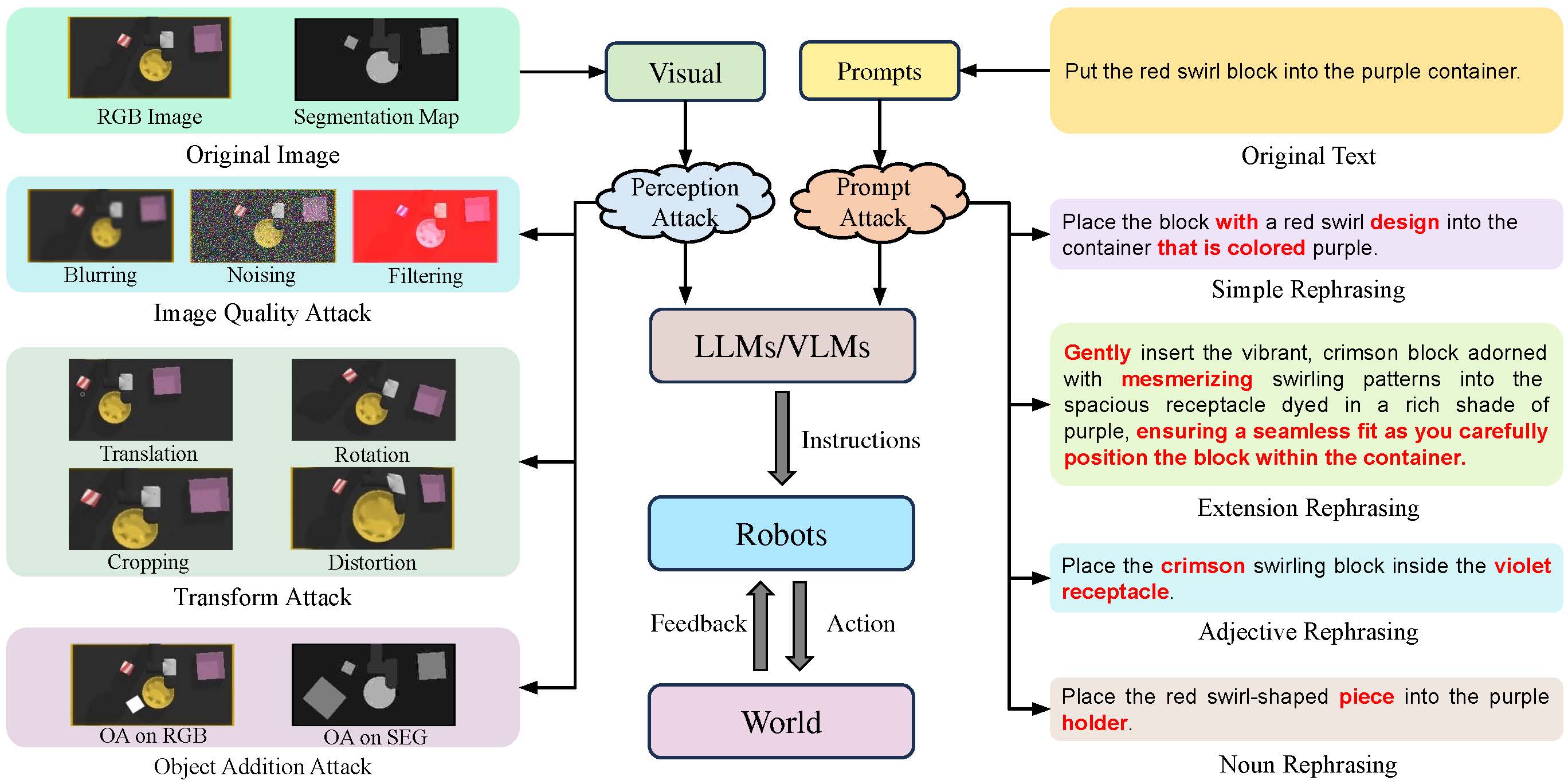
In this paper, we highlight the critical issues of robustness and safety associated with integrating large language models (LLMs) and vision-language models (VLMs) into robotics applications. Recent works focus on using LLMs and VLMs to improve the performance of robotics tasks, such as manipulation and navigation. Despite these improvements, analyzing the safety of such systems remains underexplored yet extremely critical. LLMs and VLMs are highly susceptible to adversarial inputs, prompting a significant inquiry into the safety of robotic systems. This concern is important because robotics operate in the physical world where erroneous actions can result in severe consequences. This paper explores this issue thoroughly, presenting a mathematical formulation of potential attacks on LLM/VLM-based robotic systems and offering experimental evidence of the safety challenges. Our empirical findings highlight a significant vulnerability: simple modifications to the input can drastically reduce system effectiveness. Specifically, our results demonstrate an average performance deterioration of 19.4% under minor input prompt modifications and a more alarming 29.1% under slight perceptual changes. These findings underscore the urgent need for robust countermeasures to ensure the safe and reliable deployment of advanced LLM/VLM-based robotic systems.
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination & Visual Illusion in Large Vision-Language Models
Tianrui Guan*, Fuxiao Liu*, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, Tianyi Zhou

Published in The 2024 Conference on Computer Vision and Pattern Recognition, 2023
Large language models (LLMs), after being aligned with vision models and integrated into vision-language models (VLMs), can bring impressive improvement in image reasoning tasks. This was shown by the recently released GPT-4V(ison), LLaVA-1.5, etc. However, the strong language prior in these SOTA LVLMs can be a double-edged sword: they may ignore the image context and solely rely on the (even contradictory) language prior for reasoning. In contrast, the vision modules in VLMs are weaker than LLMs and may result in misleading visual representations, which are then translated to confident mistakes by LLMs. To study these two types of VLM mistakes, i.e., language hallucination and visual illusion, we curated HallusionBench, an image-context reasoning benchmark that is still challenging to even GPT-4V and LLaVA-1.5. We provide a detailed analysis of examples in HallusionBench, which sheds novel insights on the illusion or hallucination of VLMs and how to improve them in the future. The benchmark and codebase will be released.
GrASPE: Graph based Multimodal Fusion for Robot Navigation in Unstructured Outdoor Environments
Kasun Weerakoon, Adarsh Jagan Sathyamoorthy, Jing Liang, Tianrui Guan, Utsav Patel, Dinesh Manocha

Published in IEEE Robotics and Automation Letters, 2023
LOC-ZSON: Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation
Tianrui Guan, Yurou Yang, Harry Cheng, Muyuan Lin, Richard Kim, Rajasimman Madhivanan, Arnie Sen, Dinesh Manocha
Published in The 2024 IEEE International Conference on Robotics and Automation, 2023
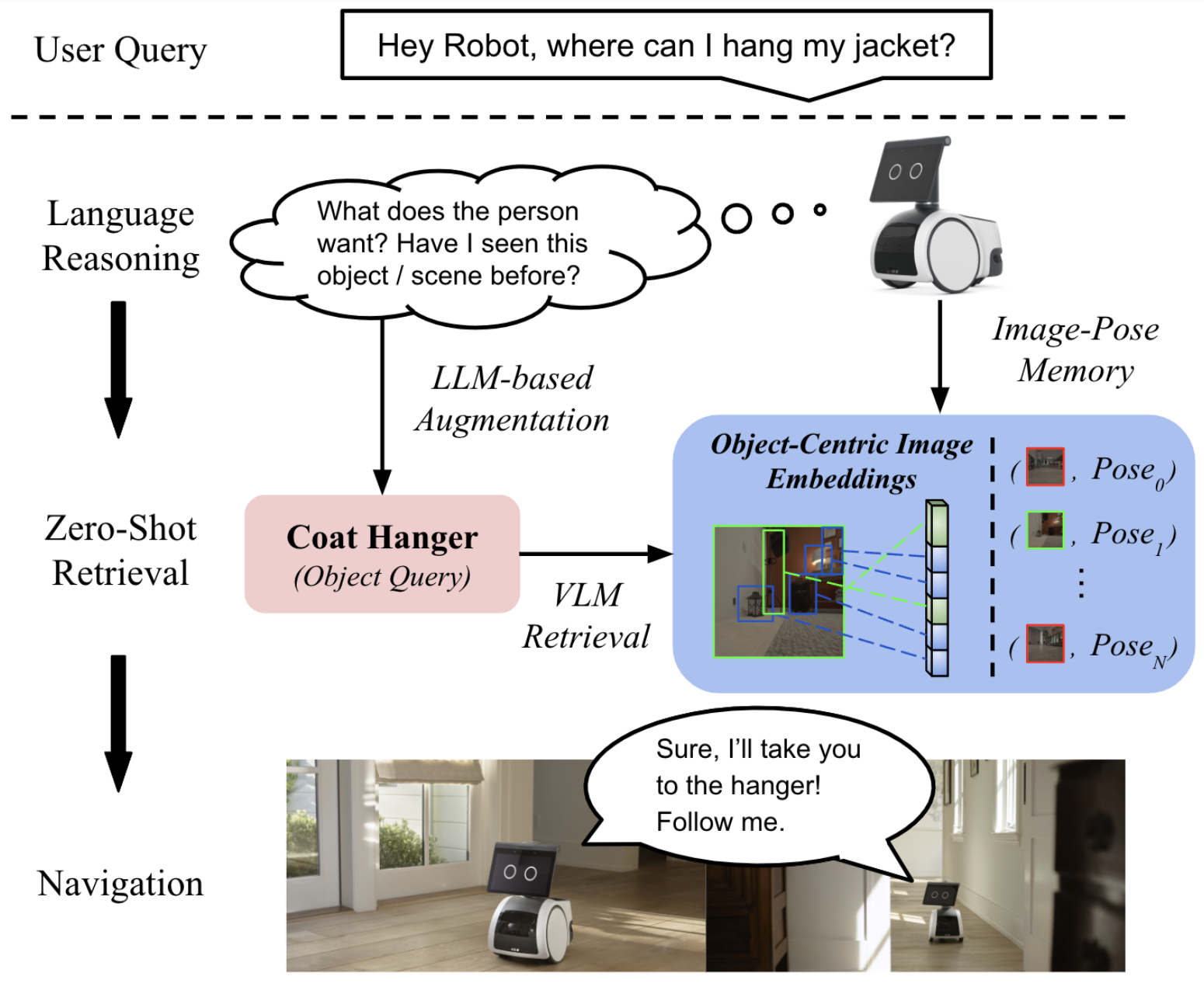
In this paper, we present LOC-ZSON, a novel Language-driven Object-Centric image representation for object navigation task within complex scenes. We propose an object-centric image representation and corresponding losses for visual-language model (VLM) fine-tuning, which can handle complex object-level queries. In addition, we design a novel LLM-based augmentation and prompt templates for stability during training and zero-shot inference. We implement our method on Astro robot and deploy it in both simulated and real-world environments for zero-shot object navigation. We show that our proposed method can achieve an improvement of 1.38 - 13.38% in terms of text-to-image recall on different benchmark settings for the retrieval task. For object navigation, we show the benefit of our approach in simulation and real world, showing 5% and 16.67% improvement in terms of navigation success rate, respectively.
iPLAN: Intent-Aware Planning in Heterogeneous Traffic via Distributed Multi-Agent Reinforcement Learning
Xiyang Wu, Rohan Chandra, Tianrui Guan, Amrit Singh Bedi, Dinesh Manocha

Published in Conference on Robot Learning, 2023
Navigating safely and efficiently in dense and heterogeneous traffic scenarios is challenging for autonomous vehicles (AVs) due to their inability to infer the behaviors or intentions of nearby drivers. In this work, we introduce a distributed multi-agent reinforcement learning (MARL) algorithm that can predict trajectories and intents in dense and heterogeneous traffic scenarios. Our approach for intent-aware planning, iPLAN, allows agents to infer nearby drivers intents solely from their local observations. We model two distinct incentives for agents strategies: Behavioral Incentive for high-level decision-making based on their driving behavior or personality and Instant Incentive for motion planning for collision avoidance based on the current traffic state. Our approach enables agents to infer their opponents behavior incentives and integrate this inferred information into their decision-making and motion-planning processes. We perform experiments on two simulation environments, Non-Cooperative Navigation and Heterogeneous Highway. In Heterogeneous Highway, results show that, compared with centralized training decentralized execution (CTDE) MARL baselines such as QMIX and MAPPO, our method yields a 4.3% and 38.4% higher episodic reward in mild and chaotic traffic, with 48.1% higher success rate and 80.6% longer survival time in chaotic traffic. We also compare with a decentralized training decentralized execution (DTDE) baseline IPPO and demonstrate a higher episodic reward of 12.7% and 6.3% in mild traffic and chaotic traffic, 25.3% higher success rate, and 13.7% longer survival time.
CrossLoc3D: Aerial-Ground Cross-Source 3D Place Recognition
Tianrui Guan, Aswath Muthuselvam, Montana Hoover, Xijun Wang, Jing Liang, Adarsh Jagan Sathyamoorthy, Damon Conover, Dinesh Manocha

Published in International Conference on Computer Vision, 2023
We present CrossLoc3D, a novel 3D place recognition method that solves a large-scale point matching problem in a cross-source setting. Cross-source point cloud data corresponds to point sets captured by depth sensors with different accuracies or from different distances and perspectives. We address the challenges in terms of developing 3D place recognition methods that account for the representation gap between points captured by different sources. Our method handles cross-source data by utilizing multi-grained features and selecting convolution kernel sizes that correspond to most prominent features. Inspired by the diffusion models, our method uses a novel iterative refinement process that gradually shifts the embedding spaces from different sources to a single canonical space for better metric learning. In addition, we present CS-Campus3D, the first 3D aerial-ground cross-source dataset consisting of point cloud data from both aerial and ground LiDAR scans. The point clouds in CS-Campus3D have representation gaps and other features like different views, point densities, and noise patterns. We show that our CrossLoc3D algorithm can achieve an improvement of 4.74% - 15.37% in terms of the top 1 average recall on our CS-Campus3D benchmark and achieves performance comparable to state-of-the-art 3D place recognition method on the Oxford RobotCar.
VINet: Visual and Inertial-based Terrain Classification and Adaptive Navigation over Unknown Terrain
Tianrui Guan, Ruitao Song, Zhixian Ye, Liangjun Zhang

Published in International Conference on Robotics and Automation, 2023
We present a visual and inertial-based terrain classification network (VINet) for robotic navigation over different traversable surfaces. We use a novel navigation-based labeling scheme for terrain classification and generalization on unknown surfaces. Our proposed perception method and adaptive scheduling control framework can make predictions according to terrain navigation properties and lead to better performance on both terrain classification and navigation control on known and unknown surfaces. Our VINet can achieve 98.37% in terms of accuracy under supervised setting on known terrains and improve the accuracy by 8.51% on unknown terrains compared to previous methods. We deploy VINet on a mobile tracked robot for trajectory following and navigation on different terrains, and we demonstrate an improvement of 10.3% compared to a baseline controller in terms of RMSE.
VERN: Vegetation-aware Robot Navigation in Dense Unstructured Outdoor Environments
Adarsh Jagan Sathyamoorthy, Kasun Weerakoon, Tianrui Guan, Mason Russell, Damon Conover, Jason Pusey, Dinesh Manocha

Published in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2023
We propose a novel method for autonomous legged robot navigation in densely vegetated environments with a variety of pliable/traversable and non-pliable/untraversable vegetation. We present a novel few-shot learning classifier that can be trained on a few hundred RGB images to differentiate flora that can be navigated through, from the ones that must be circumvented. Using the vegetation classification and 2D lidar scans, our method constructs a vegetation-aware traversability cost map that accurately represents the pliable and non-pliable obstacles with lower, and higher traversability costs, respectively. Our cost map construction accounts for misclassifications of the vegetation and further lowers the risk of collisions, freezing and entrapment in vegetation during navigation. Furthermore, we propose holonomic recovery behaviors for the robot for scenarios where it freezes, or gets physically entrapped in dense, pliable vegetation. We demonstrate our method on a Boston Dynamics Spot robot in real-world unstructured environments with sparse and dense tall grass, bushes, trees, etc. We observe an increase of 25-90% in success rates, 10-90% decrease in freezing rate, and up to 65% decrease in the false positive rate compared to existing methods.
TNS: Terrain Traversability Mapping and Navigation System for Autonomous Excavators
Tianrui Guan, Zhenpeng He, Ruitao Song, Dinesh Manocha, Liangjun Zhang

Published in Robotics: Science and Systems, 2022
We present a terrain traversability mapping and navigation system (TNS) for autonomous excavator applications in an unstructured environment. Our system can adapt to changing environments and update the terrain information in real-time. Moreover, we present a novel dataset, the Complex Worksite Terrain (CWT) dataset, which consists of RGB images from construction sites with seven categories based on navigability. Our novel algorithms improve the mapping accuracy over previous SOTA methods by 4.17-30.48% and reduce MSE on the traversability map by 13.8-71.4%. We have combined our mapping approach with planning and control modules in an autonomous excavator navigation system and observe 49.3% improvement in the overall success rate. Based on TNS, we demonstrate the first autonomous excavator that can navigate through unstructured environments consisting of deep pits, steep hills, rock piles, and other complex terrain features.
FAR: Fourier Aerial Video Recognition
Divya Kothandaraman, Tianrui Guan, Xijun Wang, Sean Hu, Ming Lin, Dinesh Manocha

Published in European Conference on Computer Vision, 2022
We present an algorithm, Fourier Activity Recognition (FAR), for UAV video activity recognition. Our formulation uses a novel Fourier object disentanglement method to innately separate out the human agent (which is typically small) from the background. Our disentanglement technique operates in the frequency domain to characterize the extent of temporal change of spatial pixels, and exploits convolution-multiplication properties of Fourier transform to map this representation to the corresponding object-background entangled features obtained from the network. To encapsulate contextual information and long-range space-time dependencies, we present a novel Fourier Attention algorithm, which emulates the benefits of self-attention by modeling the weighted outer product in the frequency domain. Our Fourier attention formulation uses much fewer computations than self-attention. We have evaluated our approach on multiple UAV datasets including UAV Human RGB, UAV Human Night, Drone Action, and NEC Drone. We demonstrate a relative improvement of 8.02% - 38.69% in top-1 accuracy and up to 3 times faster over prior works.
M3DeTR: Multi-representation, Multi-scale, Mutual-relation 3D Object Detection with Transformers
Tianrui Guan*, Jun Wang*, Shiyi Lan, Rohan Chandra, Zuxuan Wu, Larry Davis, Dinesh Manocha

Published in Winter Conference on Applications of Computer Vision, 2022
We present a novel architecture for 3D object detection, M3DeTR, which combines different point cloud representations (raw, voxels, bird-eye view) with different feature scales based on multi-scale feature pyramids. M3DeTR is the first approach that unifies multiple point cloud representations, feature scales, as well as models mutual relationships between point clouds simultaneously using transformers. Our method achieves state-of-the-art performance on the KITTI 3D object detection dataset and Waymo Open Dataset.
GANav: Efficient Terrain Segmentation for Robot Navigation in Unstructured Outdoor Environments
Tianrui Guan, Divya Kothandaraman, Rohan Chandra, Adarsh Jagan Sathyamoorthy, Kasun Weerakoon, Dinesh Manocha

Published in IEEE Robotics and Automation Letters, 2021
We propose GANav, a novel group-wise attention mechanism to identify safe and navigable regions in off-road terrains and unstructured environments from RGB images. Our approach classifies terrains based on their navigability levels using coarse-grained semantic segmentation. Our novel group-wise attention loss enables any backbone network to explicitly focus on the different groups features with low spatial resolution. Our design leads to efficient inference while maintaining a high level of accuracy compared to existing SOTA methods.
Forecasting Trajectory and Behavior of Road-Agents Using Spectral Clustering in Graph-LSTMs
Rohan Chandra, Tianrui Guan, Srujan Panuganti, Trisha Mittal, Uttaran Bhattacharya, Aniket Bera, Dinesh Manocha

Published in IEEE Robotics and Automation Letters, 2020
We present a novel approach for traffic forecasting in urban traffic scenarios using a combination of spectral graph analysis and deep learning. We predict both the lowlevel information (future trajectories) as well as the high-level information (road-agent behavior) from the extracted trajectory of each road-agent. Our formulation represents the proximity between the road agents using a weighted dynamic geometric graph (DGG). We use a two-stream graph-LSTM network to perform traffic forecasting using these weighted DGGs. The first stream predicts the spatial coordinates of road-agents, while the second stream predicts whether a road-agent is going to exhibit overspeeding, underspeeding, or neutral behavior by modeling spatial interactions between road-agents. Additionally, we propose a new regularization algorithm based on spectral clustering to reduce the error margin in long-term prediction (3-5 seconds) and improve the accuracy of the predicted trajectories. We evaluate our approach on the Argoverse, Lyft, Apolloscape, and NGSIM datasets and highlight the benefits over prior trajectory prediction methods.
Other Publications
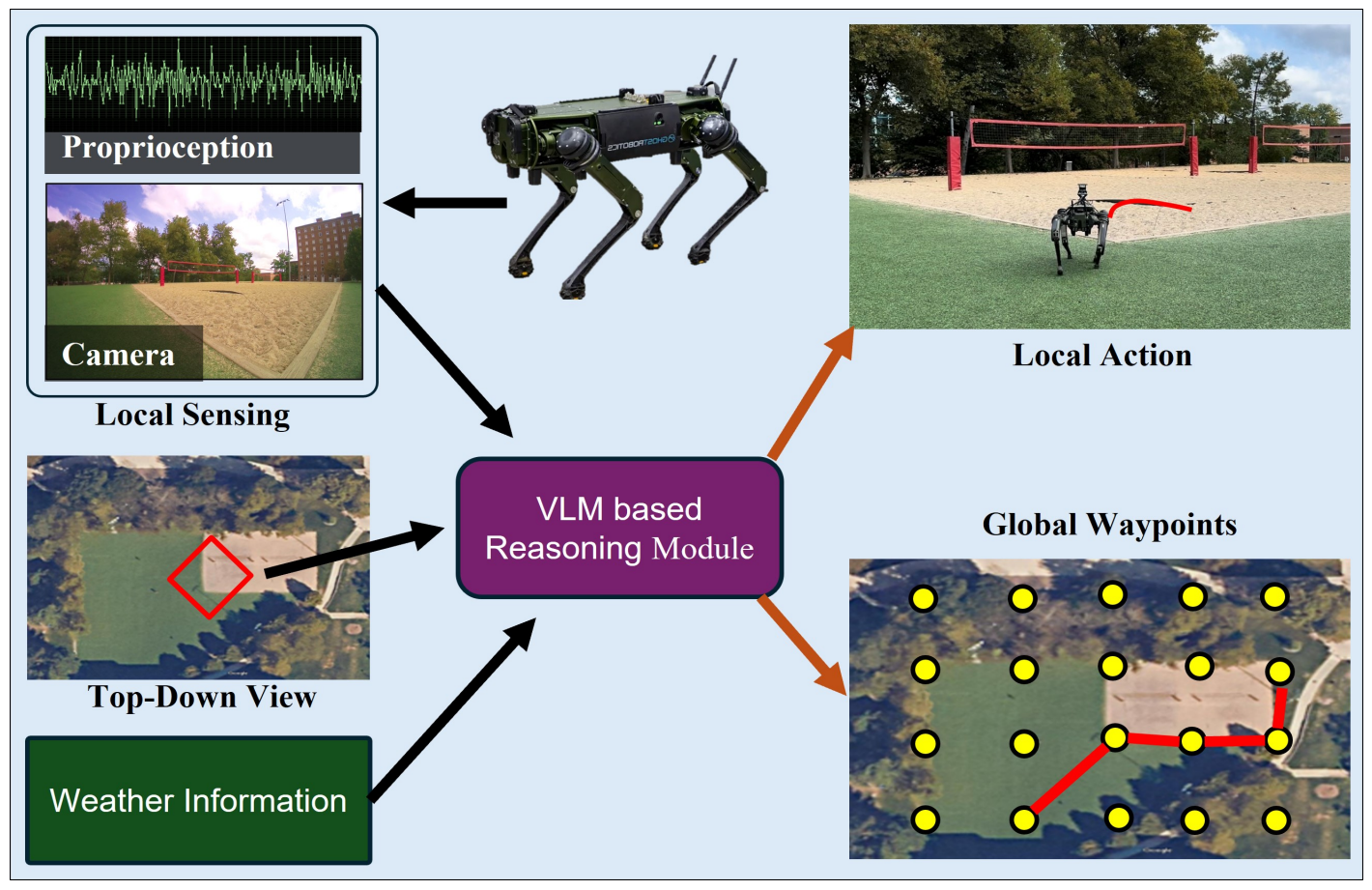
Robot Navigation Using Physically Grounded Vision-Language Models in Outdoor Environments
Mohamed Elnoor, Kasun Weerakoon, Gershom Seneviratne, Ruiqi Xian, Tianrui Guan, Mohamed Khalid M Jaffar, Vignesh Rajagopal, Dinesh Manocha
Published in Arxiv, 2024
SOAR: Self-supervision Optimized UAV Action Recognition with Efficient Object-Aware Pretraining
Ruiqi Xian, Xiyang Wu, Tianrui Guan, Xijun Wang, Boqing Gong, Dinesh Manocha
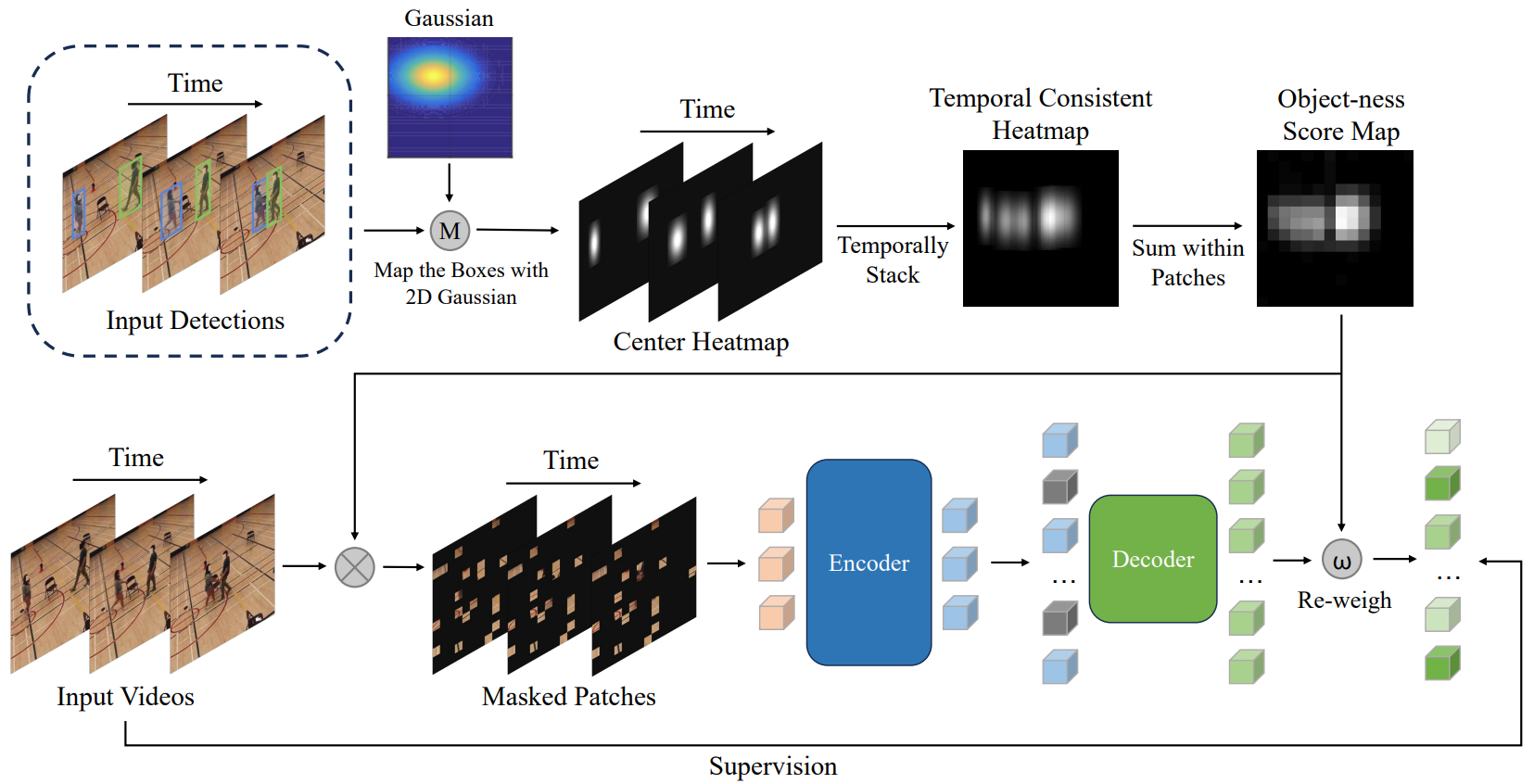
Published in Arxiv, 2024
AMCO: Adaptive Multimodal Coupling of Vision and Proprioception for Quadruped Robot Navigation in Outdoor Environments
Mohamed Elnoor, Kasun Weerakoon, Adarsh Jagan Sathyamoorthy, Tianrui Guan, Vignesh Rajagopal, Dinesh Manocha
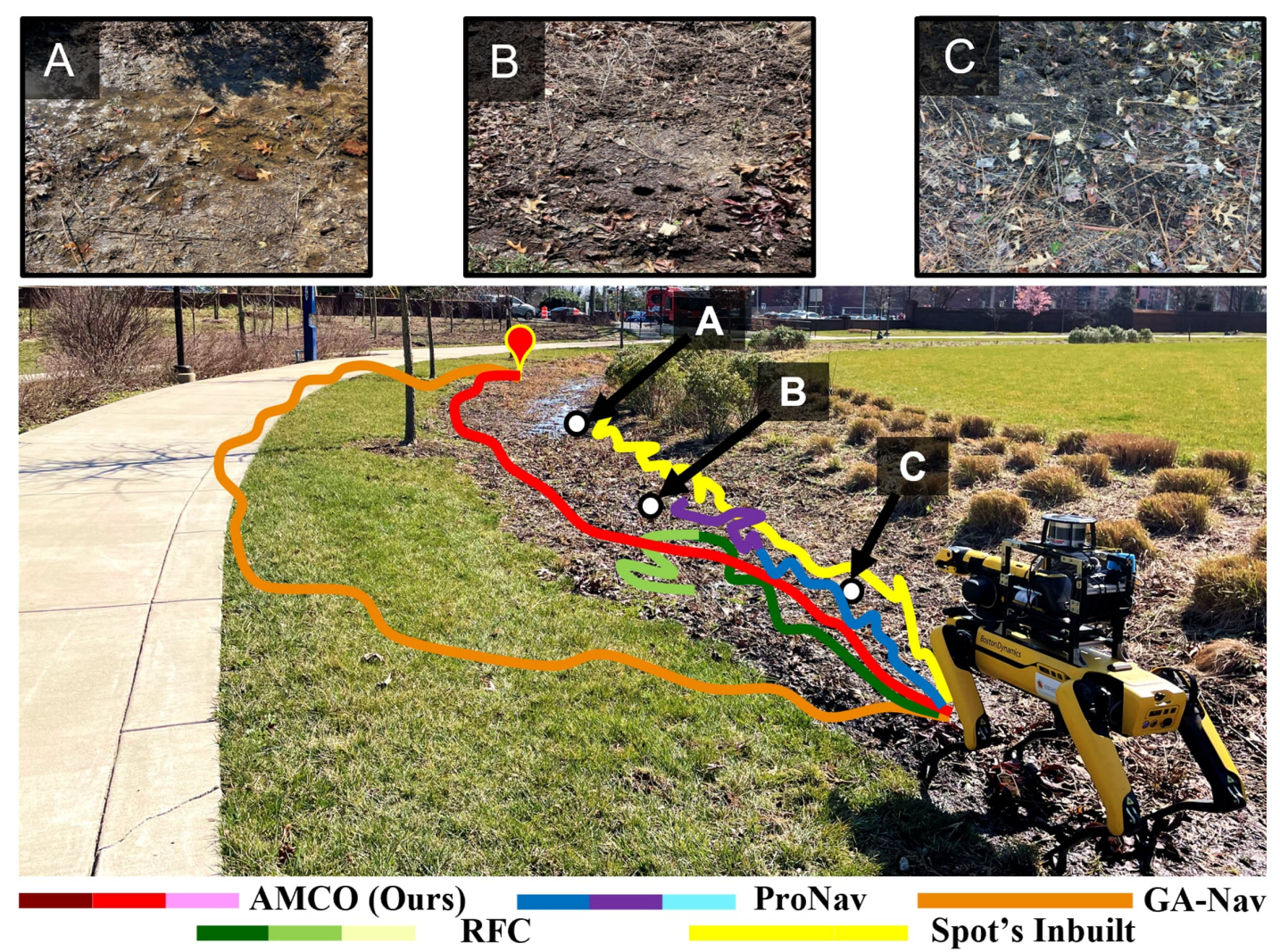
Published in The 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024
Large language models and causal inference in collaboration: A comprehensive survey
Xiaoyu Liu, Paiheng Xu, Junda Wu, Jiaxin Yuan, Yifan Yang, Yuhang Zhou, Fuxiao Liu, Tianrui Guan, Haoliang Wang, Tong Yu, Julian McAuley, Wei Ai, Furong Huang
Published in Arxiv, 2024
SCP: Soft Conditional Prompt Learning for Aerial Video Action Recognition
Xijun Wang*, Ruiqi Xian*, Tianrui Guan, Fuxiao Liu, Dinesh Manocha
Published in The 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2023
AZTR: Aerial Video Action Recognition with Auto Zoom and Temporal Reasoning
Xijun Wang*, Ruiqi Xian*, Tianrui Guan, Celso M. de Melo, Stephen M. Nogar, Aniket Bera, Dinesh Manocha

Published in International Conference on Robotics and Automation, 2023
AdaptiveON: Adaptive Outdoor Local Navigation Method for Stable and Reliable Actions
Jing Liang, Kasun Weerakoon, Tianrui Guan, Nare Karapetyan, Dinesh Manocha

Published in IEEE Robotics and Automation Letters, 2023
TerraPN: Unstructured Terrain Navigation using Online Self-Supervised Learning
Adarsh Jagan Sathyamoorthy, Kasun Weerakoon, Tianrui Guan, Jing Liang, Dinesh Manocha

Published in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2022
OF-VO: Reliable Navigation among Pedestrians Using Commodity Sensors
Jing Liang, Yi-Ling Qiao, Tianrui Guan, Dinesh Manocha

Published in IEEE Robotics and Automation Letters, 2021
Frozone: Freezing-Free, Pedestrian-Friendly Navigation in Human Crowds
Adarsh Jagan Sathyamoorthy, Utsav Patel, Tianrui Guan, and Dinesh Manocha

Published in IEEE Robotics and Automation Letters, 2020
DenseCAvoid: Real-time Navigation in Dense Crowds using Anticipatory Behaviors
Adarsh Jagan Sathyamoorthy*, Jing Liang*, Utsav Patel, Tianrui Guan, Rohan Chandra, and Dinesh Manocha

Published in IEEE International Conference on Robotics and Automation, 2020
RobustTP: End-to-End Trajectory Prediction for Heterogeneous Road-Agents in Dense Traffic with Noisy Sensor Inputs

Published in ACM Computer Science in Cars Symposium, 2019
You can also find my articles on my Google Scholar profile. –>